
Nach dem ich mich in einem vorangegangenen Beitrag mit der Aufbereitung von Geländemodellen für die Visualisierung beschäftigt habe, ist nun die Landbedeckung (land cover) an der Reihe. Dafür existieren einige freie Datensätze, die hauptsächlich durch die Klassifizierung von Fernerkundungsdaten gewonnen wurden. Ich habe hier die CORINE-Daten von 2012 verwendet, die Europa weit in relativ hoher Auflösung (100 m sowie 250 m) verfügbar sind.
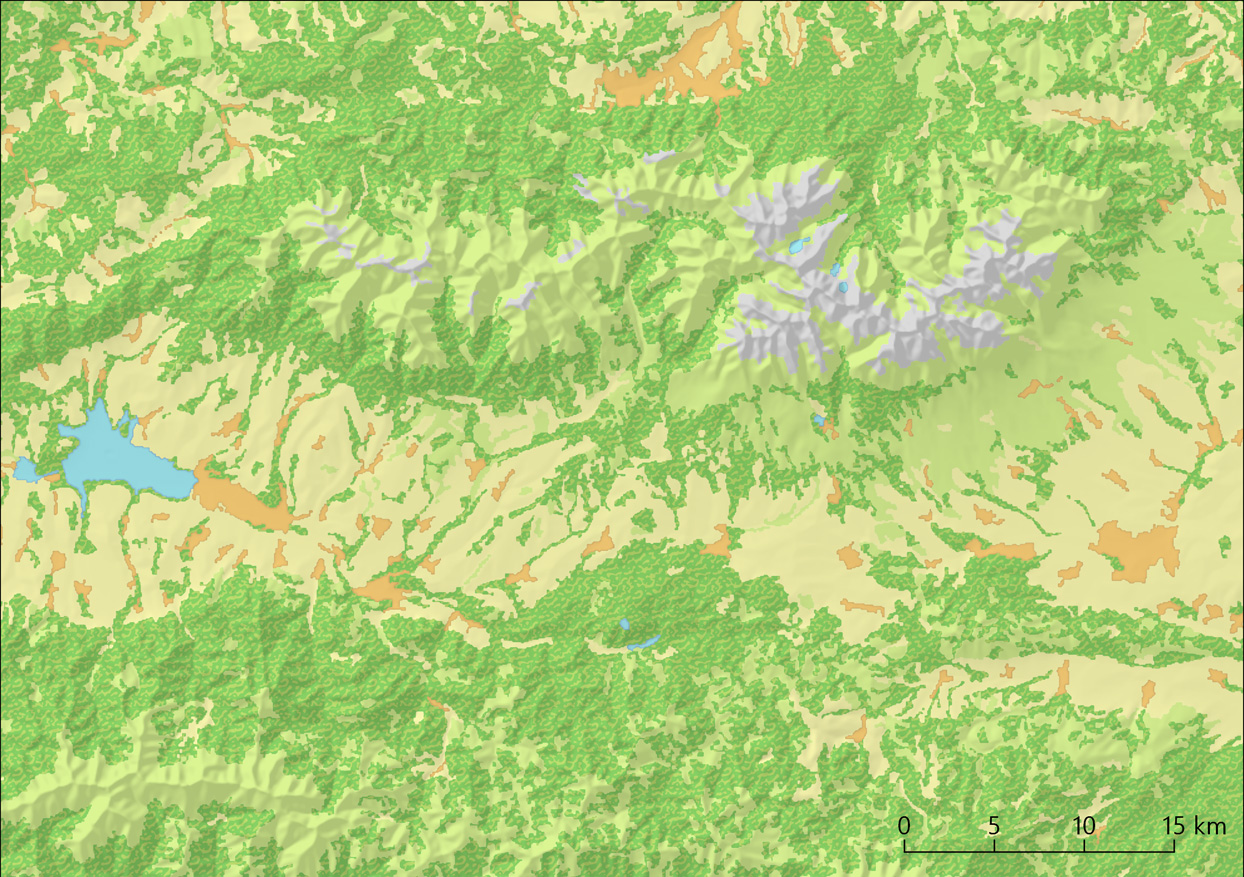
Weil mir das Relief so gut gefiel, habe ich mich dafür entschieden, dass Beispiel der Hohen Tatra noch ein wenig auszubauen. Die Beispielgrafiken sind der besseren Vergleichbarkeit halber alle in einer Galerie zusammengefasst, die sich am Ende des Beitrages befindet. Zu sehen ist immer der gleiche Kartenausschnitt mit meinen unterschiedlich aufbereiteten Versionen der Landbedeckung und den Ausgangsdaten. Zu Beginn sind die ursprünglichen Daten zu sehen.
Der erste Versuch (1) war noch recht einfach gedacht: Wald, Feld, Wasser und Fels als neue Klassen und mit einfach Farben dargestellt. Zur Generalisierung habe ich einen Median-Filter eingesetzt um die Klassengrenzen zu glätten. Das Ergebnis überzeugte mich noch nicht so wirklich. Also warf ich einen Blick in einen Atlas, wie dort die Klassen gewählt wurden und orientierte mich daran. (Ich möchte an dieser Stelle die These aufstellen, dass ein Schulatlas nachhaltig das Weltbild prägt – der Kenner sollte aus der Visualisierung schließen können, mit welchem Atlas ich aufgewachsen bin…)
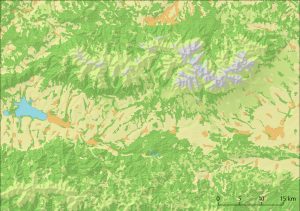
Also alles frisch erstellt für den zweiten Versuch (2): Noch Wiesen einzuführen gibt nicht nur die Landbedeckung besser wieder, sondern in gewisser Weise auch die Höhenstufen im Gebirge. Das Ergebnis wird nun schon anschaulicher, zumal es noch verstärkt wird durch die Textur für den Wald. Nicht, dass diese unbedingt notwendig wäre. Aber sie sorgt für ein belebteres Bild und erhöht die Autoplausibilität. Dennoch wurden für mich zwei Schwächen deutlich: Vergleicht man mit dem Ausgangsmodell sieht man, dass die durchaus dominanten Siedlungsflächen fehlen sowie das die Farbgebung insgesamt noch nicht so wirklich stimmig ist.
Die nächste Darstellung (3) ist schon wesentlich schöner anzusehen und bringt Strukturen wesentlich besser hervor. Dafür sind noch ein paar kleine grafische Effekte hinzu gekommen um das Ergebnis plastischer wirken zu lassen. Aber auch ein neues Problem traten damit auf: es gibt auf einmal viele kleine Flächen, von denen einige zu klein sind für den gewählten Maßstab.
Variante (4) zeigt den misslungen Versuch eine Generalisierung nur mit Filtern in mehreren Durchläufen sowie unterschiedlichen Kernel-Größen. Der Informationsverlust ist enorm und irgendwie wirkt es alles sehr „rundgelutscht“ für diesen doch noch relativ detaillierten Maßstab. Also auf zum Literaturstudium um eine bessere Lösung zu finden…
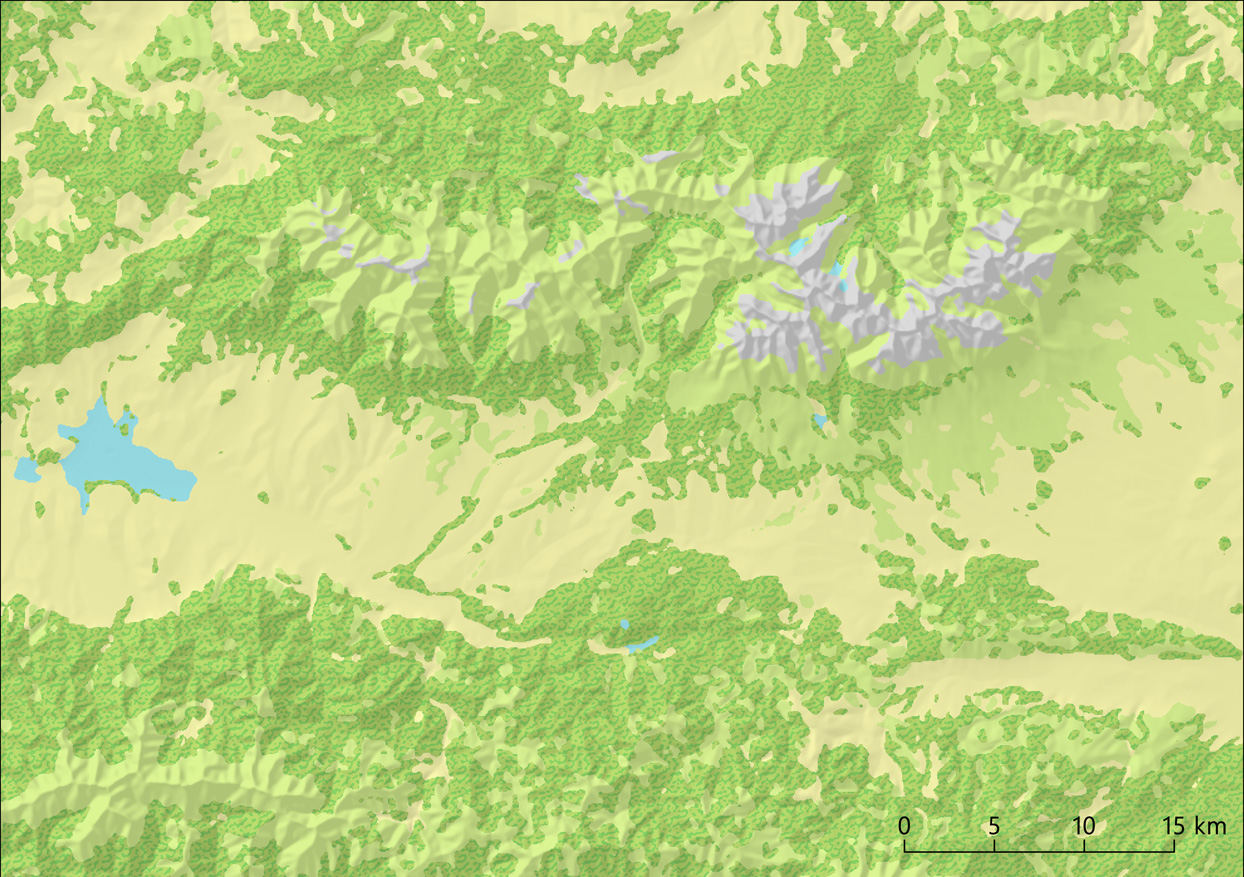
… am Ende ging es doch recht schnell und einfach. Einfach einen Mehrheitsfilter nutzen und zu kleine Regionen löschen und dann mittels erneuten Filterdurchgängen (mit kleinen Kerneln) wieder mit Daten füllen. Auf diese Weise bleiben Strukturen erhalte, Mindestdimensionen werden eingehalten und das Ergebnis (5) ist durchaus ansehnlich. Ohne Frage fehlt da noch so einiges für eine richtige Karte. Aber die Ebnen Landnutzung wäre damit fertig.
-
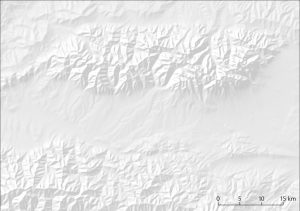
- Geschummerte Geländedarstellung der Hohen Tatra.

-

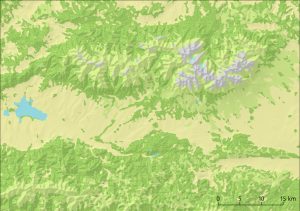
- Corine Land Cover 2012

-

- (1) Erster Versuch einer Reklassifizierung.

-
- (2) Neue Klassifizierung und Wald mit Texttur
-
- (3) Neue Klassifizierung und angepasste Textur für den Wald.
-

- (4) Versuch einer besseren Generalisierung.

-
- (5) Endgültige Generalisierung und Visualisierung.
Noch zwei Hinweise zum Schluss: Wer auf der Suche nach Mustern ist sollte beim USGS nachschauen. Hier gibt es eine große Auswahl in unterschiedlichen Formaten, die sich auf diverse Anwendungsfälle übertragen lassen sollten. So ein schönes Pattern für den Wald hätte ich wohl nicht so schnell erstellen können. Aufbereitet musste es natürlich werden um in QGIS in die Visualisierung einfließen zu können. Als Arbeitsablauf hat sich bei mir ein wenig herauskristallisiert QGIS für die Visualisierung und GRASS GIS für die Prozessierung der Daten einzusetzen. Ich finde so können beide Programme ihre Stärken optimal ausspielen.
Schreibe einen Kommentar