Im Rahmen meiner Arbeit an Webkarten bin ich ein wenig in das Problem der Auswahl von Punkten hineingestolpert und war gezwungen mir die dafür existierenden Lösungen anzusehen. Das Problem: Es gibt viele Städte, Berge, Aussichtspunkte, usw. die man gerne auf einer Karte darstellen möchte. Aber wie wählt man die relevanten Punkte für den Kartennutzer aus? Der absolute Zahlenwert hilft selten weiter, in Sachsen ist eine Stadt mit mehr als 100.000 Einwohner bedeutend, ein Berg über 1.000 Meter, aber was ist das schon in der Relation gesehen? In den Alpen sind 1.000 Meter für einen Berg lächerlich wenig, wie in China eine Stadt mit weniger als einer Million Einwohnern. Man muss also einen Punkt im Kontext seiner „Nachbarn“ betrachten. Ist ein Punkt also gegenüber den Punkten in seiner Umgebung mehr oder weniger wichtig? Die Höhe oder Einwohnerzahl ist da zumindest schon mal ein Kriterium, welches man heranziehen kann um es in Relation zu anderen Punkten zu setzen.
Auswahl von Städten nach der Einwohnerzahl
Am Beispiel von Städten und deren Einwohnerzahl möchte ich das Problem kurz beschreiben. Die folgende Karte zeigt alle Städte, getaggt als „town“ oder „city“ bei OpenStreetMap für die Umgebung für Dresden. Weil es so viele sind, ist eine Beschriftung nicht möglich, aber auch so wäre keine gute Auswahl! Eine Auswahl nach der Bevölkerungszahl funktioniert, hat aber ihre Schwächen in Regionen mit vielen Städte wie hier im Oberschlesischen Industriegebiet. In dünn besiedelten Gebieten sieht man dafür kaum Städte, aber wären die hier nicht sogar noch wichtiger?
-
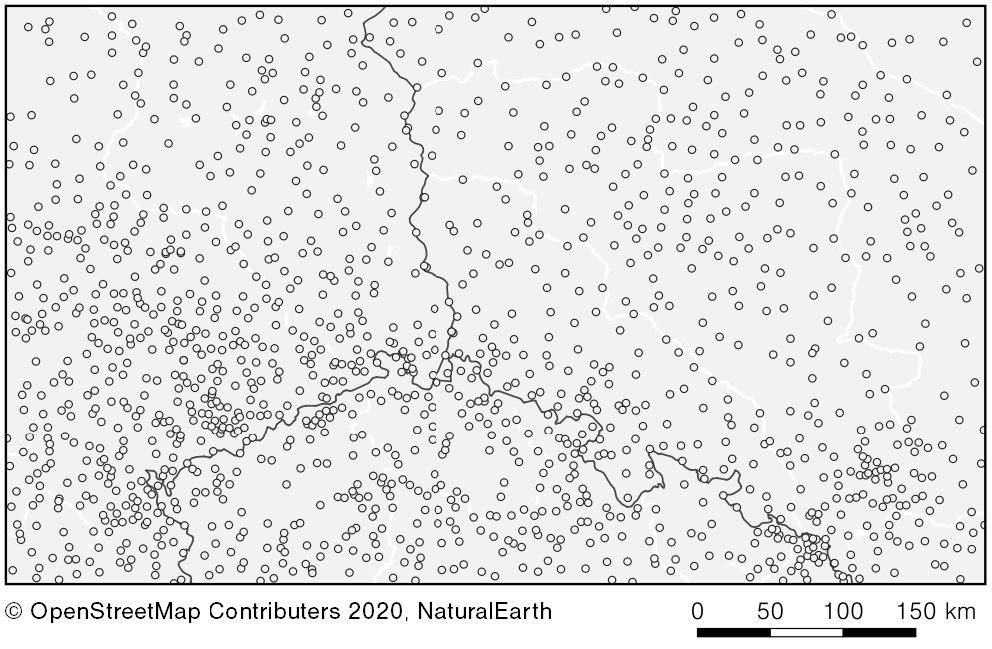
- Alle Städte rund um Dresden
-

- Auswahl nach der Bevölkerungszahl
Bei meiner Recherche bin ich auf zwei mögliche Lösungen gestoßen. Zum einen wäre da das „Label Grid“, was vor allem bei Webkarten zur Anwendung kommt. Wie funktioniert der Ansatz? Es wird ein Gitter erstellt und in jeder Gitterzelle der Punkt mit dem höchsten Wert (zum Beispiel der Einwohnerzahl) ausgewählt. Das Ergebnis ist eine sehr homogene Verteilung, welche im Wesentlichen durch das Gitter bestimmt wird. Der andere Ansatz nennt sich Funktionelle Bedeutung. Es wird mit Hilfe einer Funktion der Einfluss eines Ortes moduliert und in Relation zu den umliegenden Orten gesetzt. Hier sind mögliche Ergebnisse bei der Anwendung der Methoden:
-
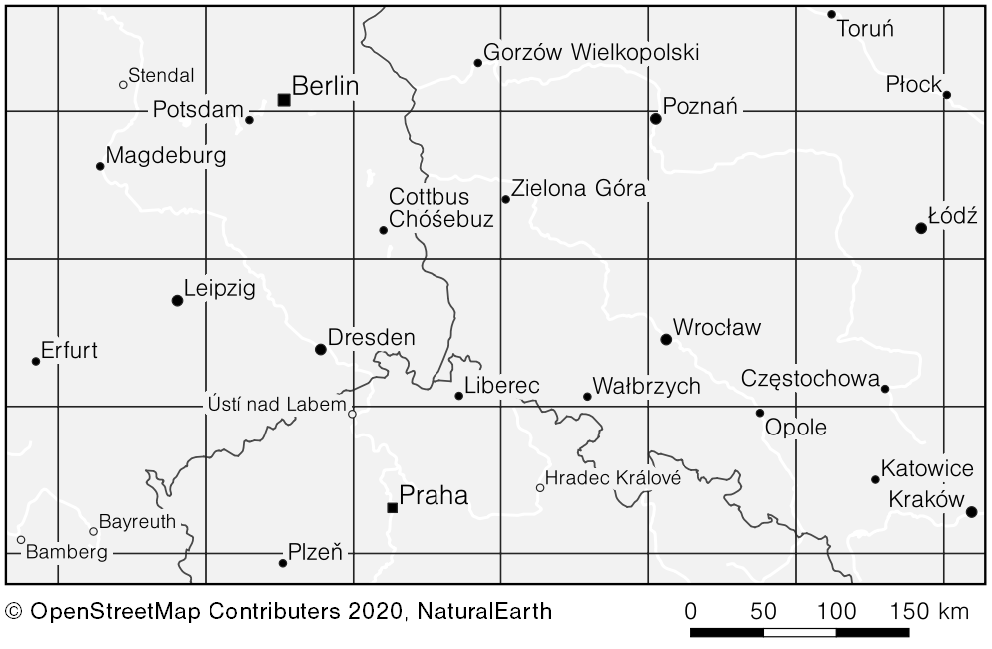
- Auswahl mittels des Label Grid Ansatzes
-
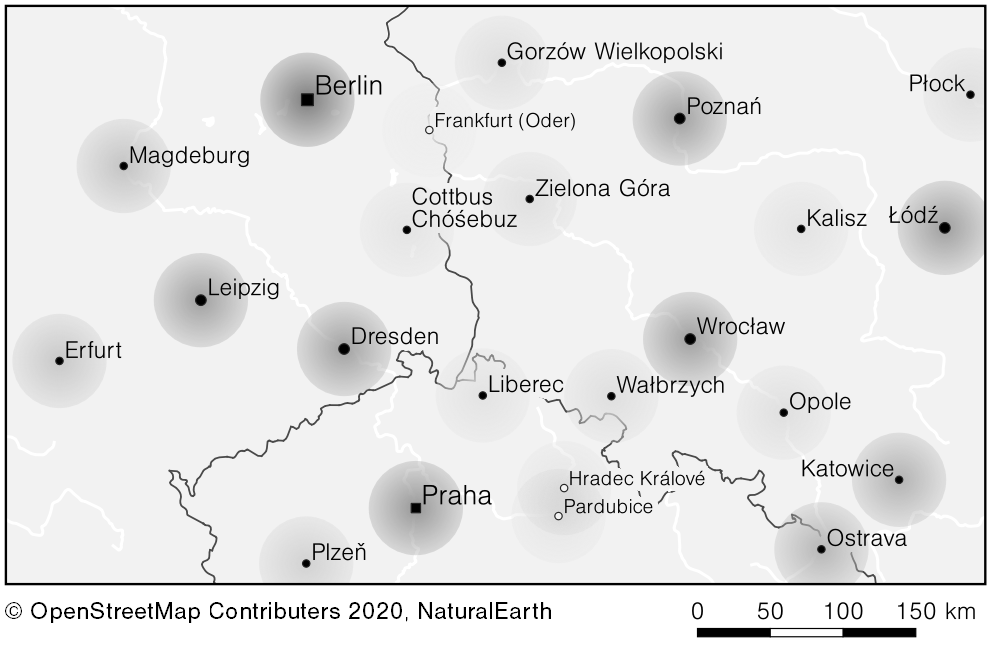
- Auswahl mittels der Funktionellen Bedeutung
Mir kam da noch eine eigene Idee: warum nicht die Dominanz verwenden? In der Geographie versteht man darunter ein Maß für einen Gipfel, dass die Distanz zum nächsten höheren Punkt beschreibt, Achtung nicht Gipfel! Nun könnte man ja die Einwohnerzahl der Städte als Höhenwert sehen, daraus eine Oberfläche berechnen und wüsste dann wie weit die Entfernung zum nächsten Punkt mit höherem (Einwohner-) Wert ist! Puh, warum erste eine Oberfläche (Relief) errechnen? Es geht doch ebenso, wenn man nur die Städte als Punkte berücksichtigt und die Distanz zur nächstgelegenen Stadt mit mehr Einwohner berechnet. Somit werden nur abstrakt die Punkte betrachtet und keine kontinuierliche Oberfläche. Zur Abgrenzung habe ich das Prinzip Diskrete Dominanz (engl. discrete isolation) getauft.
Ein Beispiel: nimmt man Dresden mit seiner Einwohnerzahl und sucht nach der nächsten Stadt mit mehr Einwohnern, so findet man Leipzig. Die Strecke Dresden-Leipzig ist damit die Diskrete Distanz für Dresden; im Umkreis von 100 km gibt es keinen Ort mit mehr Einwohnern. Berechnet man die Dominanz für alle Städte, so kann man über einen minimalen Distanzwert auswählen welche Städte man auf der Karte sehen möchte und wie dicht die Karte mit Orten belegt ist. Natürlich kann man das Maß der Diskreten Dominanz für die Auswahl noch mit anderen Attributen kombinieren, im letzten Beispiel habe ich das mit dem Place-Type (city, town) gemacht und jeweils unterschiedliche Werte benutzt. Das Ergebnis eine gut gefüllte Karte, die jeweils lokal die wichtigsten Städte zeigt.
-

- Darstellung der Diskreten Dominanz für Dresden
-

- Auswahl mittels Diskreter Dominanz
-
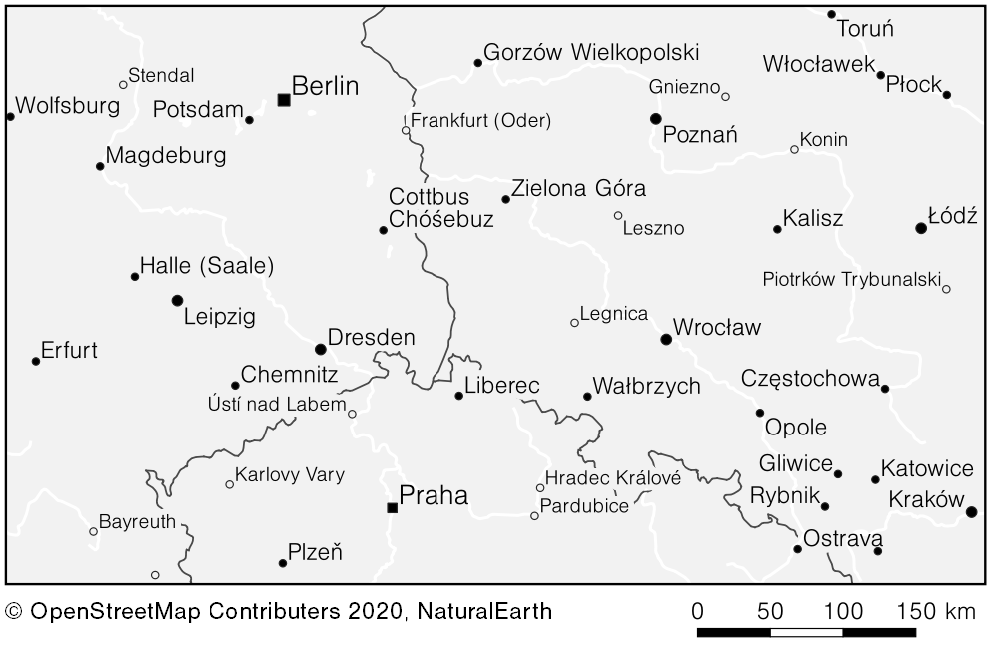
- Auswahl mittels Diskreter Isolation und des Place-Types von OpenStreetMap
Das QGIS-Plugin
Soweit das schöne Beispiel, aber wie macht man es nun? Einfach mein neues QGIS-Plugin als Erweiterung installieren und anwenden! Über „Erweiterung installieren…“ das Plugin „Point Selection“ installieren und schon hat man die Tools in den Geoverabreitungswerkzeugen. Wer ganz genau wissen möchte was im Hintergrund passiert, kann im GitHub Repository nachschauen. Eine kurze Gebrauchsanleitung habe ich als Hilfe im jeweiligen Werkzeug hinterlegt. Auf GitHub findet sich ebenfalls noch ein Beispiel mit Bergen zum Ausprobieren. Es ist natürlich möglich das Prinzip ebenfalls auf andere Daten zu übertragen. Es müssen nur eben Punkt mit einem nummerischen Attribut sein.
Also viel Freude beim Ausprobieren und Auswählen. Falls Fehler auftauchen, freue ich mich natürlich über Hinweise!
Ein Tool des QGIS-Plugins
Schreibe einen Kommentar